上一章给大家安利了一下搜索结果页优化的原理,或者叫个人看法。搜索结果页的引流和转化。各个模块的优化运营方式与指标。那么这一章就来好好探讨下,站内搜索的流程,用户的搜索词是经过怎样一个流程最后变成呈现在我们面前的搜索结果页的。
为了便于大家理解,这里还是用一张通俗易懂的流程图给大家瞧瞧,,有个大概的脉络,我也会依照此脉络给大家介绍。话不多说,上图!(为了显得不那么有产品味道,通俗易懂,我将其简化了很多)
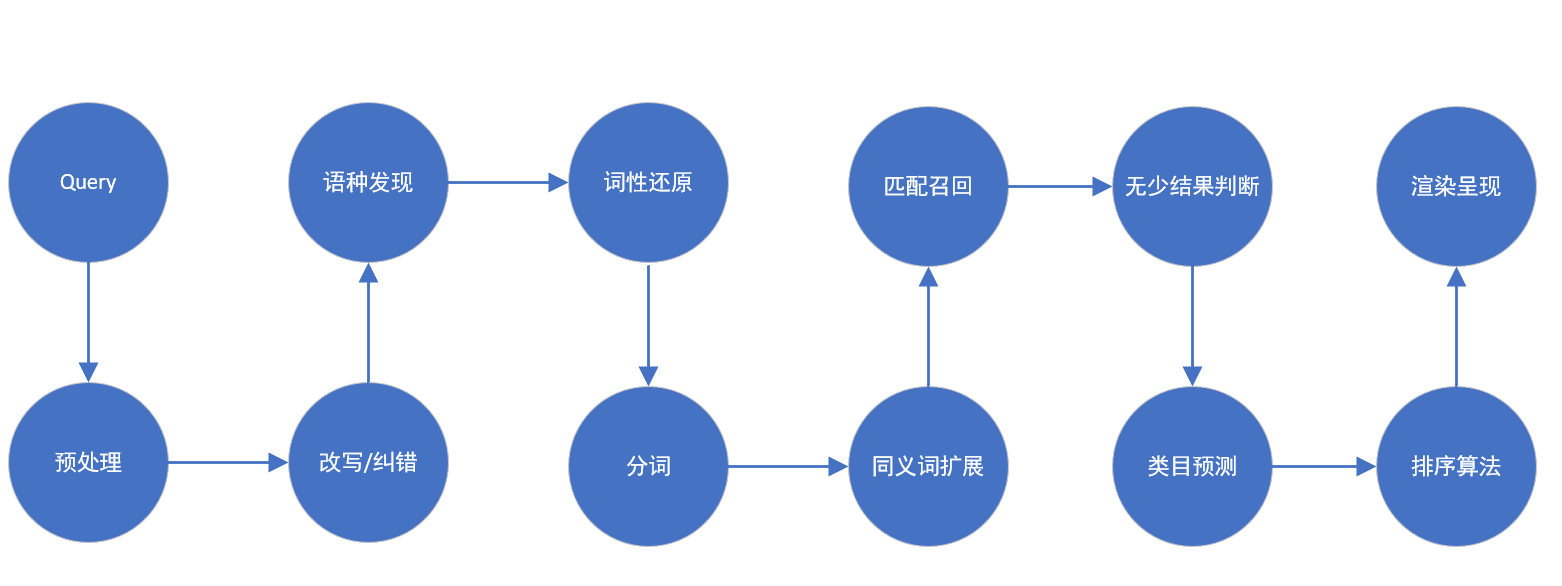

一般而言,干劈流程是没啥味道的,所以我们就带着例子进去走一遍,差不多就了解了,先声明一下,我说的不一定对,切勿盲从。
我们先从汉语开始,关键词为“男士的印花T恤”
首先会进入预处理环节,此环节会将该关键词的无用部分进行去除,比如停用词。其中“的”就是我们要砍掉的部分,其实在预处理阶段还会有剔除一些左右两边无用的空格等,那么如何确定停用词呢,在汉语里面任何词可能都有用,但是在特定的语言环境下,许多的词组就成为了停用词,比如淫秽词,极限敏感词(参考广告法)等。
经过预处理环节之后,进入智能纠错或者人工改写环节,需要判断这个关键词是否有错别字(算法/人工词库),是否命中人工改写的词库(暴君功能)。
经过这一环节处理后,进入到语种识别环节,国内电商也是支持英语环境的,此时会对该关键词进行语种识别,确认该词应该在哪种语言环境里搜索,有的电商是没有这个环节的,因为确实没有必要。对于出口型跨境电商而言就显得很有必要,像速卖通,虾皮,亚马逊等。
此时进入词性还原阶段,词性还原顾名思义,针对英语就是单复数还原,时态还原,词干提取等,对于汉语而言则是识别其中关键词主干,男士印花T恤(预处理已经把“的”给去掉了),整个词都是主干。
随后进入分词阶段,此时分词系统会对“男士印花T恤”进行分词,一般而言汉语会进行n-gram多粒度分词。分词结果如下:男/士/印/花/t/恤/男士/印花/T恤/男士印花/印花T恤/男士T恤/。
对于上面的ngram不了解的也没关系,后续专门的算法章节会讲到。对于一些音型文字比如英语,法语,印尼语等使用的空格分词法,就是按照关键词之间的空格比如 “women dress”分词结果则直接从空格处进行切词。
为啥和汉语不同呢,其实英语也有多粒度切词,和汉语的切词方式都是基于词典里的词组合理性进行的,但是汉语与音型语言有着些许区别。
这里延展一下:音型语言与结构形语言在语言含义上有着两种决然不同的含义容量与精度。即单词含义容量:单个单词语言含义表达范围;精度:单个单词语言精准描述的范围值,范围值越小精度值越高。
结构形语言的起源来自于象形文字,即以物品的形状来结构文字,排除文学性的表达,基本的文字的表达内容需要多个单词组成完整精确的意义,单个文字的含义容量广泛,缺乏精度。
音型语言文字起源于对于字母拼接,较少的字母组合形成字根,用以作为语言延伸的基础。通过较少的字根来扩展获得更多的语义词汇,以此作为层级来拓展词汇分支。由词根变化向外扩展,变形越小含义越接近词根,变形越大含义越远离词根
因此得出个假设结论:
音型文字:音型文字单词含义容量范围较低,精度值高;
汉语:象形结构形文字,单词含义容量范围高,精度值低。
汉语搜索采用多粒度词组切词的分词方式很大程度上是基于汉语搜索的单词含义容量较大造成精度不准,所以需要用多个单字组成词来确认搜索词的具体含义。
我们来体验一下:
query(汉语):男士印花T恤。切词:男/士/印/花/t/恤/男士/印花/T恤/男士印花/印花T恤/男士T恤/;
query(英语):Men Print T-Shirt 切词: men/print/t-shirt/men t-shirt/print t-shirt/。
两者的原理都大致相同,额外的说这些,只是想让大家明白不同语言之间分词是有些许差异的,并不能“一招鲜吃遍天”。
上一篇:电商运营之站内搜索全面指南(四) 下一篇:内容类电商流量变现,这三个环节缺一不可
郑重声明:本文版权归原作者所有,转载文章仅为传播更多信息之目的,如作者信息标记有误,请第一时间联系我们修改或删除,多谢。
